Making the monolith testable


To write reproducible and isolated tests, we need two things :
- Isolate global mutable state to the same scope as the test. Either the state can be scoped to the test or the test needs to isolate that global state.
- Control the inputs and outputs of a piece of code. That means faking the network, database, disk, clock, etc.
We can combine an Hexagonal Architecture with Dependency Injection to produce a testable services for the next steps. Bringing a legacy monolith to such a testable architecture has been my main job for a few years now. It is a large endeavor, but it can be done testable piece by testable piece to incremental reap the benefits.
Alternatively (or temporarily), the entire monolith can be treated as a black box service, but that requires preparing files and databases prior to the test and possibly launching the SuT in isolated processes. Tests will be slow, coverage analysis will be less meaningful because of inter-dependencies and environment variations will cause flakiness.
Components
I will refer to each individual service in the hexagonal architecture as a Component to make it clear this is not necessarily part of a microservice ecosystem. I'll also classify the Adapters that connect Components as either Contracts or Protocols.
A Contract may be an actual REST/gRPC API, an object oriented interface, a dynamic library with exported functions, etc. It is an immediate dependency from one Component to another with the usual versioning requirements of a synchronous dependency.
A Protocol may be a file format, a database schema, the JSON schema of a message queue, etc. It is an asynchronous dependency and it has more complex backward and sometimes forward combability requirements. As such, the protocol is usually versioned in itself without being bound to the version of the consumer. These are the hardest things to change in a system and designing them deserves the appropriate amount of effort.
Test Coverage
Testers, product managers and developers see test coverage quite differently. The opposing views come from measuring code coverage VS requirements coverage.
Code coverage is pretty easy to monitor, but that measure is like a badly trained AI : 100% confident yet no less wrong. So smart people dug into that problem and made up new more stringent criteria like covering all branches permutations or mutation testing. But that leads to an astronomic number of tests and it doesn't really help choosing which of those tests are the most valuable.
On the other hand, requirements coverage sounds great. Make a test for everything you want to keep working. The value of the test is a combination of the value of the feature times the risk of breaking it in the future. That can work quite fine except for two things :
- The list of requirements for a brown field project of a moderate size is not easy to gather.
- Without clear contracts and protocols between components, the whole of the system needs to be tested as one single big black box. It requires significant engineering investments to build the test infrastructure around a monolith.
I like to use a combination of these methods : Use code coverage gaps to discover untested requirements. And in large monolithic systems, I've actually also found dead code this way a few times...
How to test
Coverage analysis gives us way to list and prioritize what to test, but it doesn't help with the "how".
A good starting point is the testing trophy.
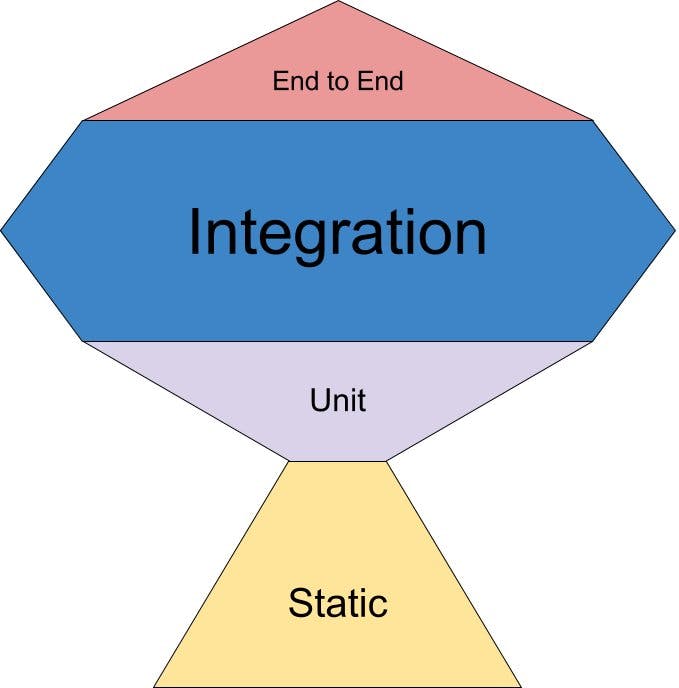
E2E tests are used to find Component availability and Contract/Protocol versioning issues. It launches the entire product and might uses UI Automation to do a shallow test of a Component. If one of these tests fails, either there an issue with the testing infrastructure or the whole Component is out. In the case of microservices, this would run in production as much as possible to monitor services availability.
Component tests are the acceptance criteria for the feature. It launches only the Component with faked dependencies, so it should run fairly quickly and represent the largest investment in test automation. When a component test fails, its name and failure details should indicate what part of the feature is broken for end users.
Unit tests serve as development accelerators. Test-Driven development using Component tests should work well most of the time, but implementing specific algorithms sometimes works better with tests of a smaller scope.
Static tests is an interesting addition to the typical vision of tests. This refers to static analysis which is a bit outside of the scope of this post, but is enormously important nevertheless.
A side-quest worth mentioning is non-functional requirement tests, specifically performance. These could be Component tests like any other, but they need to be run on specific hardware and the pass condition is difficult to choose. An easier alternative is Monitoring, especially in a DevOps world.
For software that is operated by the customer on their own hardware, some industries will allow analytics collection on their system, but not ours. We therefore maintain a staging system and a benchmark suite as representative of typical user scenarios as possible.